


Python爬取高校专业特色文件,进行词频分析。
总体思路:
先根据自己要分析的专业,去找开了这个专业的学校信息,找到这些学校里这个专业的专业特色文件并下载(PDF文件),然后PDF转文本,用Python的jieba库进行词汇分析。(看不懂可以先忽略)
完整代码
1 | """ 这里用了很多库,需要自己用pip安装 |
实现过程
先来到(浏览器打开)这个页面:http://zypt.neusoft.edu.cn/hasdb/pubfiles/gongshi2017/index.html
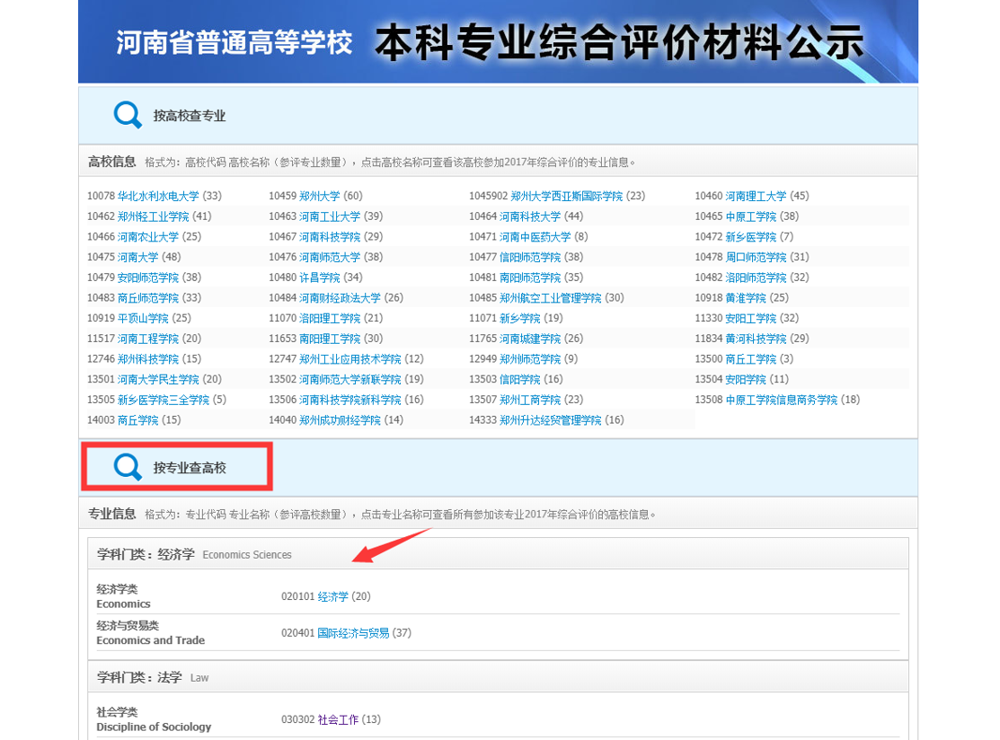
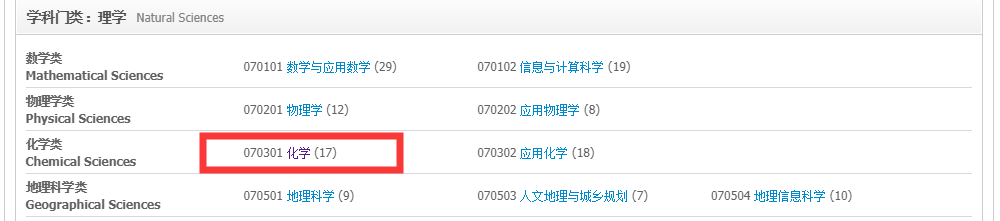
按专业查找,找到自己需要分析的专业的代号。比如我要分析的是化学的,代号是070301
python文件main函数的 index 就是http://zypt.neusoft.edu.cn/hasdb/pubfiles/gongshi2017/spec/+代号.html (这里改成你要分析的专业代号就行了,其他的全都不用改)
比如:化学专业的主页就是:

浏览器打开:
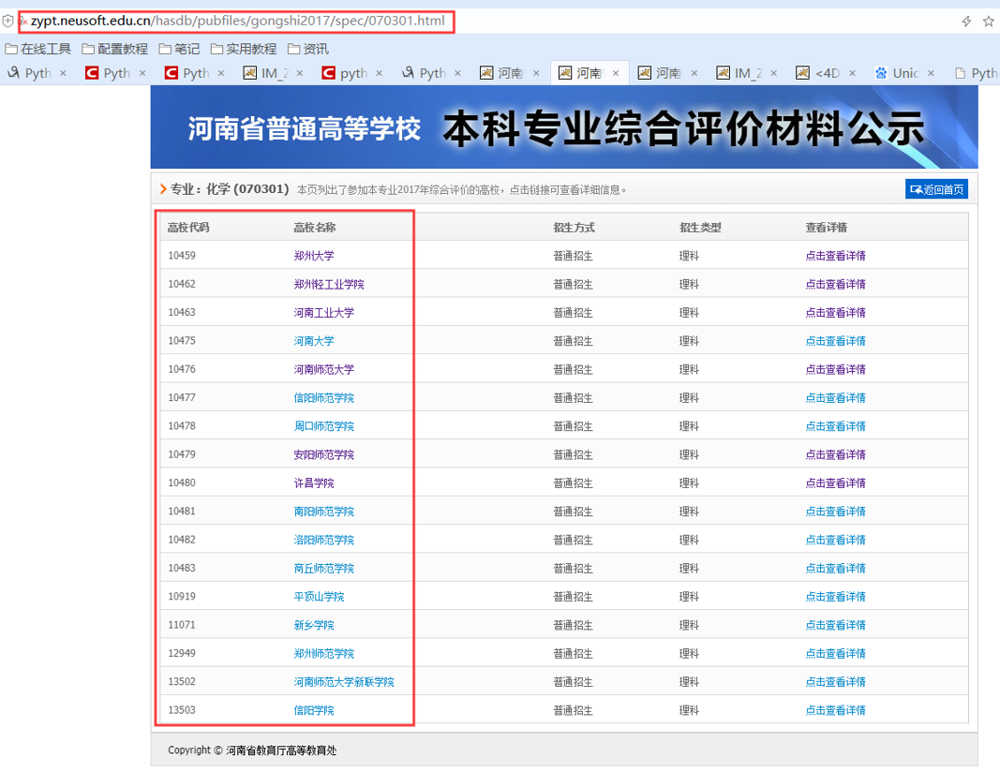
看看这些大学的链接:
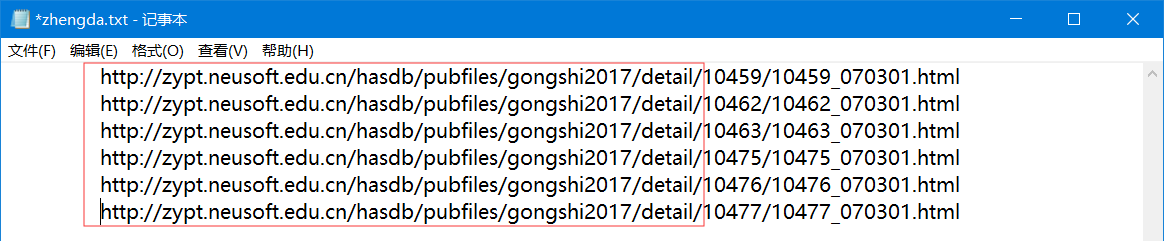
浏览器选一个大学点进去,比如我这选的郑大:
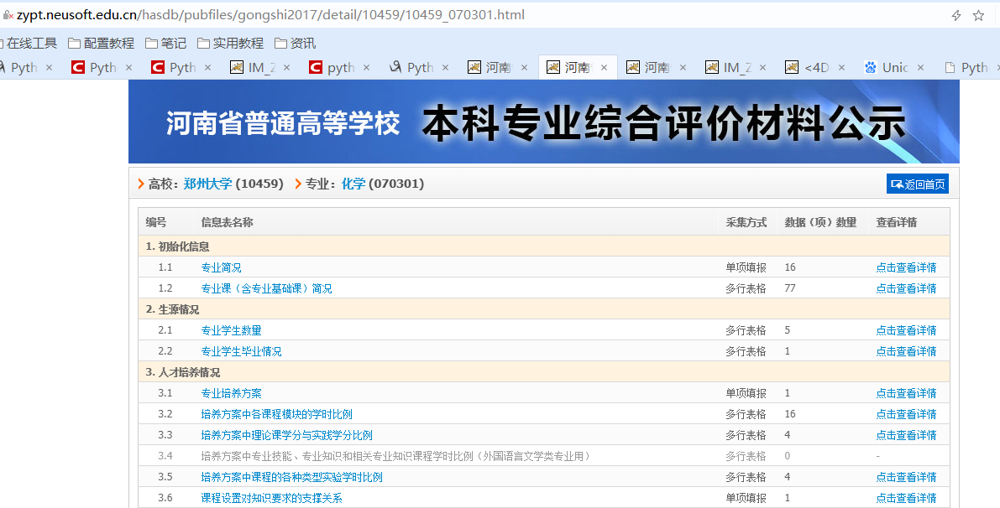
我们需要的是每个大学的 9.1 专业特色、实施过程和效果说明 里面的文件

而 9.1 专业特色、实施过程和效果说明 的链接都是这样的

所以爬取这些URL的时候需要进行拼接:
1 | # 爬取所有 `9.1 专业特色、实施过程和效果说明` 的链接 |
打开其中一个学校的 9.1 专业特色、实施过程和效果说明 页面,可以找到我们最终需要的PDF文件地址。
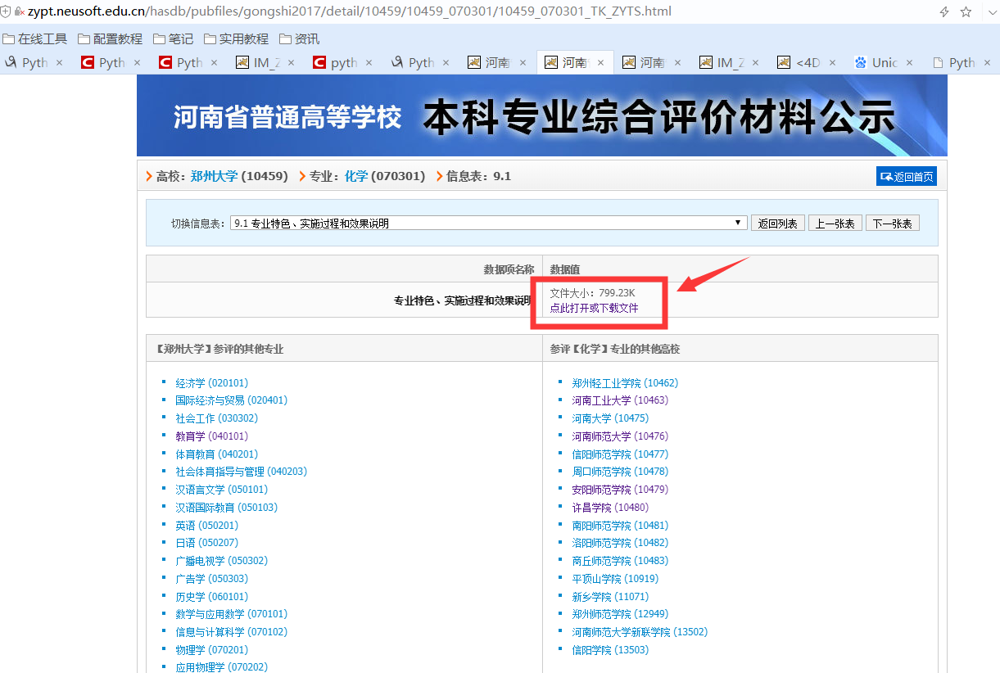
对应 GetPDFList() 函数,爬取这些PDF的URL。
1 | def GetPDFList(url_list): #爬取PDF的URL |
拿到这些URL,就可以把PDF下载下来,转成TXT文本。
1 | def parse(pdf_url): |
最后用jieba库进行分析
1 | def CPFX(): # 利用jieba库进行词频分析 |
完结、撒花✿✿ヽ(°▽°)ノ✿ . But、一个疑问贴在这里:
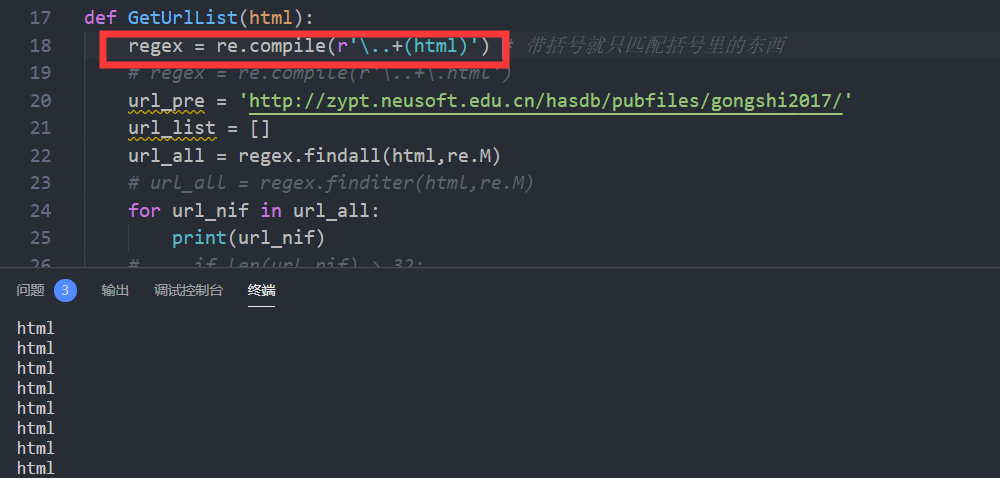
为什么re在进行正则匹配时、表达式带括号会给出意外的结果?
带括号就只匹配括号里的内容
但是带括号的,用 re 的 finditer 实际上可以匹配到正确结果
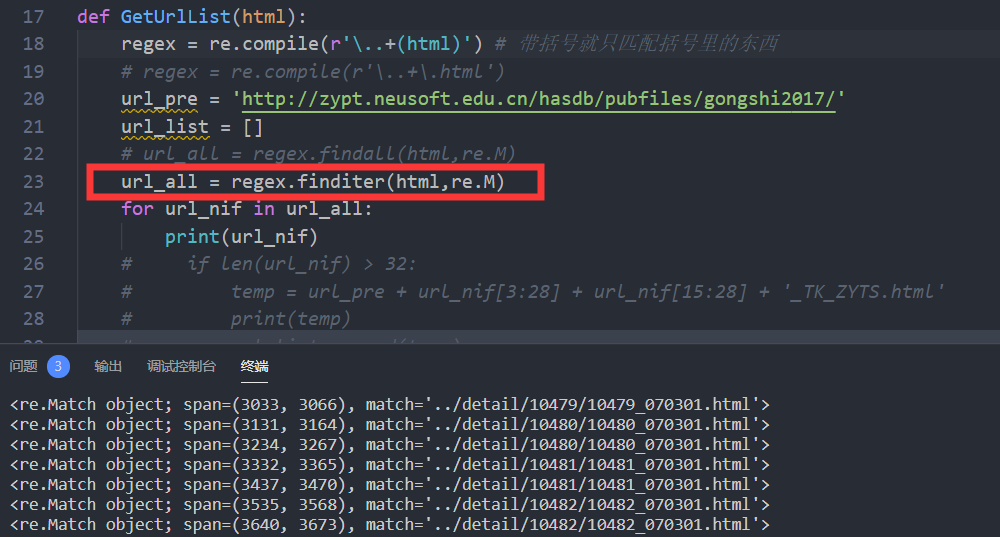
最后还是去掉括号才能正确匹配。

Why???
- 本文链接: https://anyway521.github.io/post/cfbc4d4d.html
- 最后更新:
- 版权声明: 博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议进行许可,转载请注明出处!
