


学习爬虫的入门项目。
创建项目
这里我创建了一个ScrapyProject文件夹,用来存放各个Scrapy项目,要爬的网站是:https://www.xicidaili.com/
所以项目命名为xicidailiSpider
cmd要cd到ScrapyProject目录下,然后执行
1 | scrapy startproject xicidailiSpider |
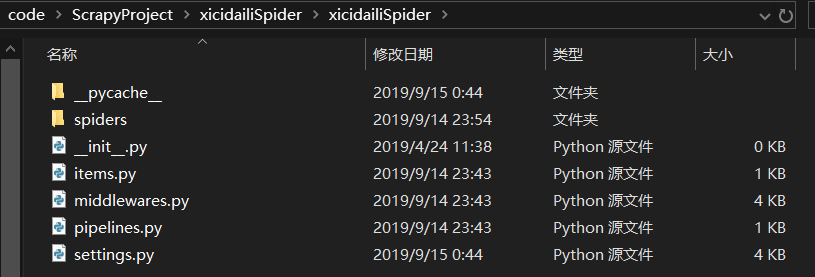
这时候 scrapy 就会自动生成项目文件,注意下文件目录xicidailiSpider文件夹下还有一个xicidailiSpider文件夹,以及一个scrapy.cfg配置文件。

打开xicidailiSpider/xicidailiSpider文件夹,可以看到这些文件,其中存放爬虫文件的就是spiders文件夹
生成爬虫文件
cmd要cd到ScrapyProject/xicidailiSpider目录下,然后执行
1 | scrapy genspider xicidaili xicidaili.com |
Ps: 注意,爬虫的.py文件不要和项目名重复

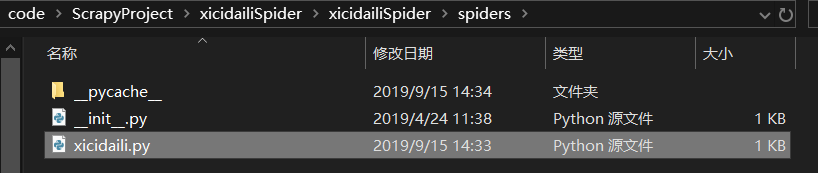
这时候会发现spiders文件夹多了一个xicidaili.py,这就是我们要的爬虫文件
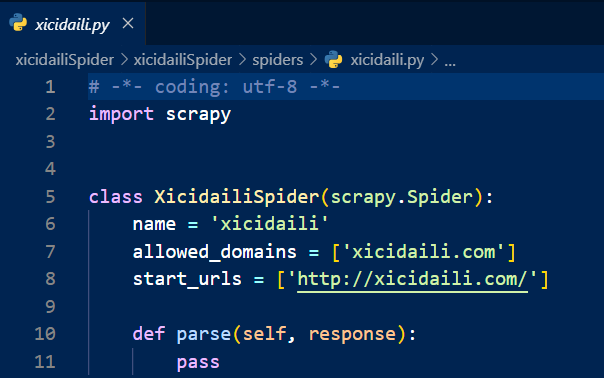
打开文件,一开始默认应该是这样的
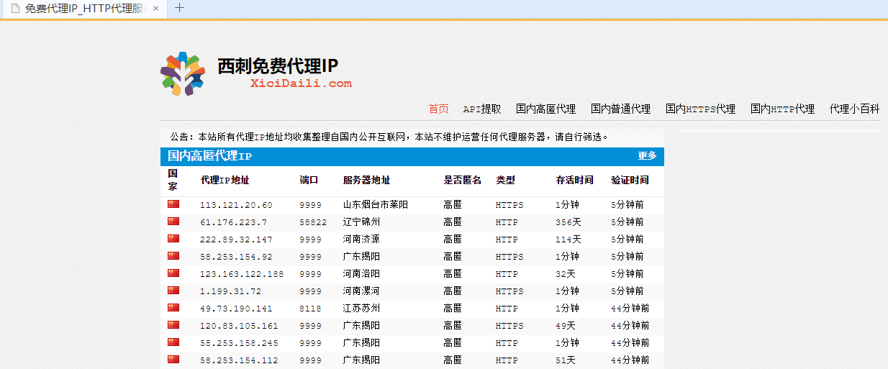
准备爬点东西下来(<tr>内的<td>标签的内容)
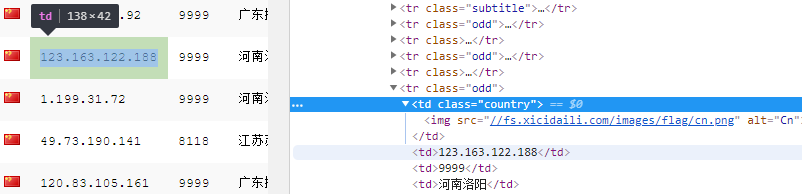
修改xicidaili.py的内容为:
1 | # -*- coding: utf-8 -*- |
Ps: 如何用正则表达式或者xpath()爬取内容需要自学
运行爬虫文件
这时候cmd还是在ScrapyProject/xicidailiSpider目录下,然后执行
1 | scrapy crawl xicidaili |
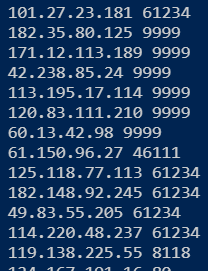
如图:

网站内容就爬下来了。
- 本文链接: https://anyway521.github.io/post/c0592fb6.html
- 最后更新:
- 版权声明: 博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议进行许可,转载请注明出处!
