


爬虫实战,批量下载多页图片。
这次选取的是 http://www.bizhi88.com
Ps: 这是一个免费下载图片的网站哟 (^U^)ノ~YO
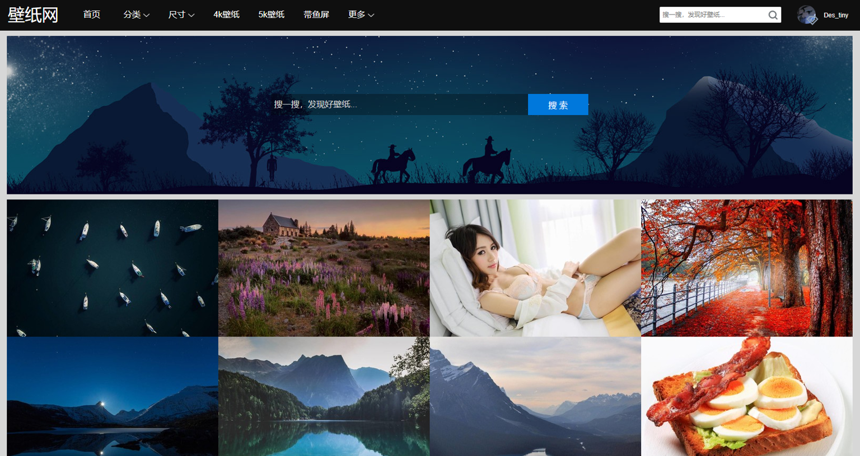
不同于百度图片的后缀直接是汉字关键词,这个网站的URL格式是:http://www.bizhi88.com/s + 关键词序号:
比如搜索框搜索星空,就会跳转到http://www.bizhi88.com/s/26/,就是星空关键词的第一页。
翻到第二页会发现,除了首页,URL后缀就都是序号.html
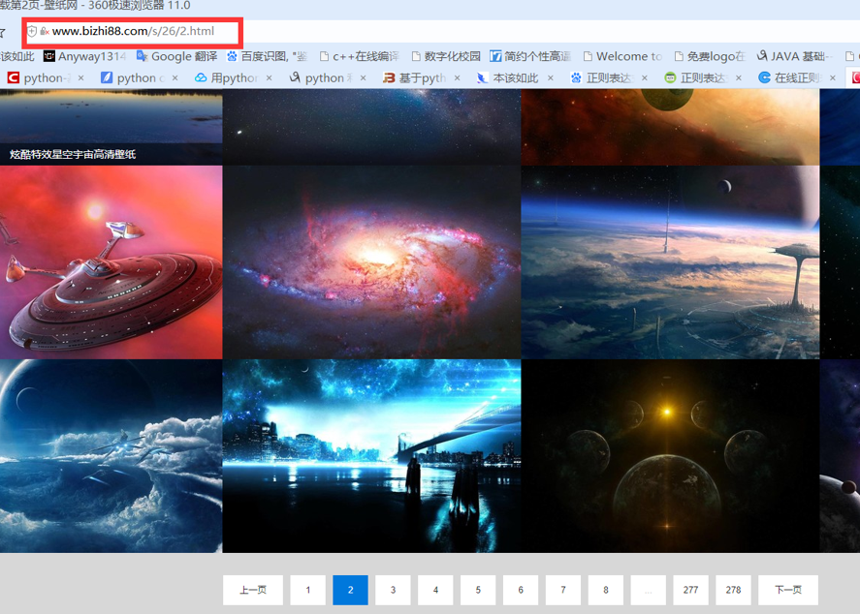
分析到这里,大概就知道该怎么做了。
最重要的其实还是正则表达式,这里推荐一个在线测试网站:**http://tool.oschina.net/regex/#** ,先拿图片网站的代码去试一试:
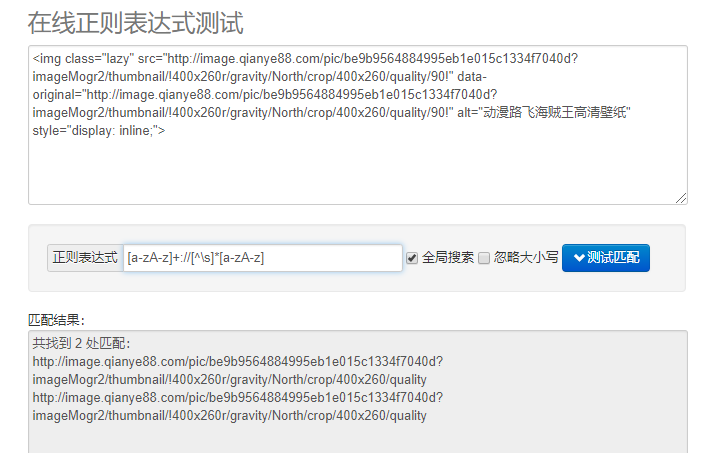
看起来没啥问题,实际用的时候,问题就现出来了。
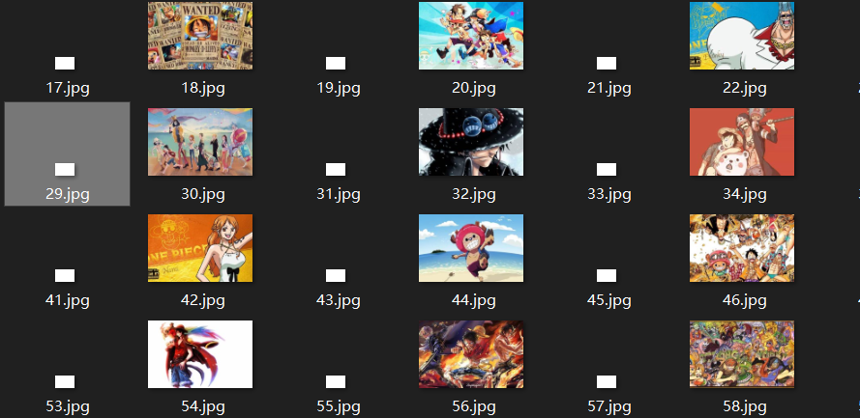
Q1:一个![]() 标签里有两个重复的URL
标签里有两个重复的URL
解决办法:用set保存
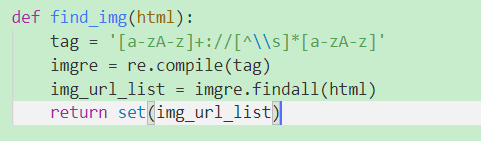
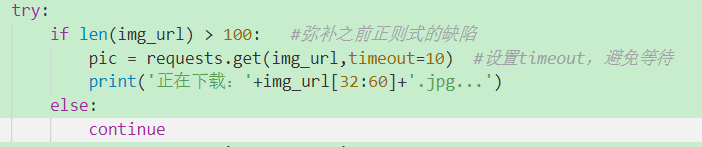
Q2:正则表达式有缺陷(新手太弱)
解决办法:URL都向合法格式靠拢(符合规则的图片格式肯定都一样)

这里通过URL长度排除不合法的
完整代码
1 | import re |
这个爬虫只是方便下载图片,适当取用,理性爬取ヾ(◍°∇°◍)ノ゙,另外,福利请拿好:
代码1:
1 | # 下载某个分组的所有图组 |
代码2:
1 | # 下载某个搜索词的图组 |
(会不会用看造化.jpg)

保重身体!!! 罒ω罒
- 本文链接: https://anyway521.github.io/post/baa3b82c.html
- 最后更新:
- 版权声明: 博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议进行许可,转载请注明出处!
