


Python学习笔记–Python-Re库( 正则表达式 )。
正则表达式常用操作符
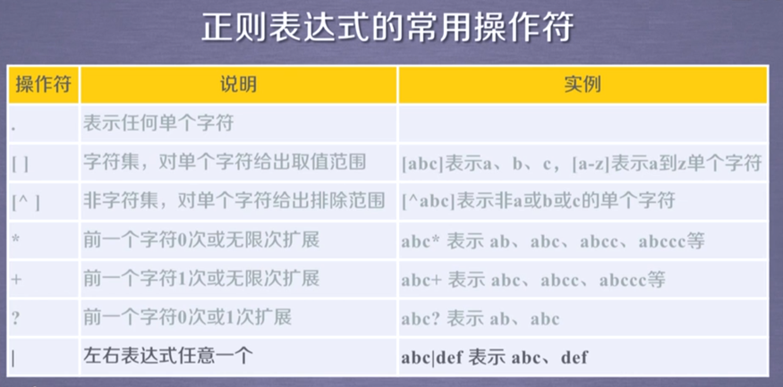
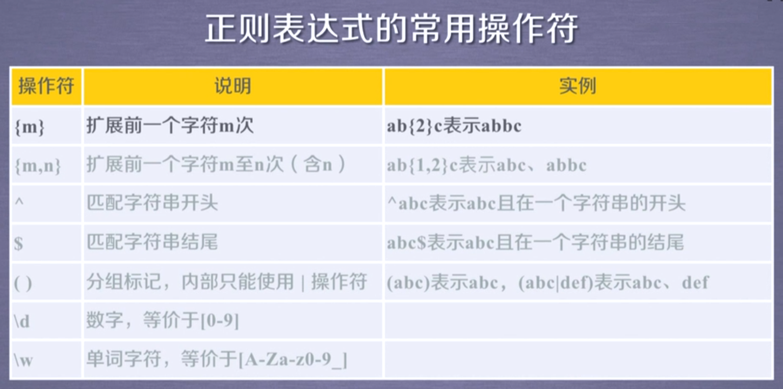
经典实例

Re库的主要函数

re.search()
作用:搜索符合正则表达式的第一个对象
1 | import re |
re.match()
作用:与re.search()类似,区别是re.match()会从每个字符串的开头进行匹配
1 | match2 = re.match(zz, stru) |
re.findall()
作用:搜索所有匹配表达式的子串,这里返回的是列表类型( 注意区别BeautifulSoup里面的soup.find_all() )
1 | stra = re.findall(zz, strs) |
re.split()
作用:将除了匹配的字符串外所有的部分分割
1 | strk = re.split(zz, strs) |
re.finditer()
作用:返回一个匹配结果的迭代类型,可以用for循环遍历每个对象
1 | for it in re.finditer(zz, strs): |
re.sub()
作用:替换掉字符串里所有匹配的对象
1 | rp = "邮编" |
以上是通俗用法,实际操作中,利用re.compile()更加方便
re.compile()
作用:将正则表达式的字符串形式编译成正则表达式对象
1 | regex = re.compile(zz) |
相比之前的通俗用法,将符合正则表达式的字符串编译后,拿这个对象继续去进行re的各类操作(search、match、findall、、、),更加简洁明了。

re库的match对象
1 | import re |
程序输出结果:
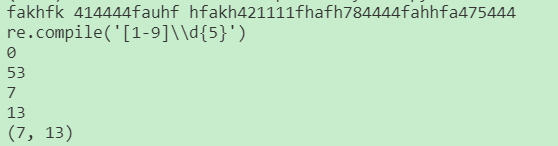
Re库默认采用贪婪匹配

最小匹配

最小匹配操作符

附:爬虫实战-淘宝代码(2019-10-9可用)
注意这里淘宝需要自己账号先登录,然后添加header里面的user-agent以及cookie:浏览器F12 -> Network -> Doc -> headers
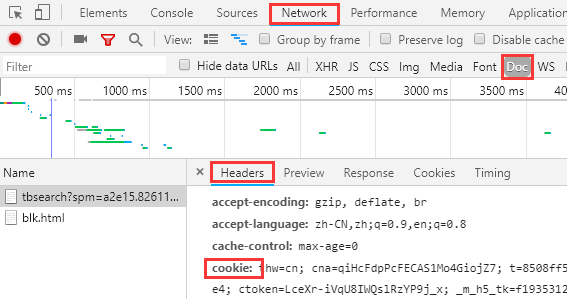
代码如下:
1 | import requests |
Ps:以上图片除标题外、均来自: 中国大学MOOC-Python网络爬虫与信息提取:https://www.icourse163.org/course/BIT-1001870001
- 本文链接: https://anyway521.github.io/post/3e6a6bf3.html
- 最后更新:
- 版权声明: 博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议进行许可,转载请注明出处!
